How To Structure Your Prompts to Get Better LLM Responses: Understanding the Anatomies of LLM Prompts


Large Language Models (LLMs) like GPT-4 and LLaMA 2 generate responses based on how prompts are structured—making prompt engineering essential for getting accurate, useful outputs.
We at Codesmith cultivate technologists who are at the intersection of society and tech, able to meet this moment and thrive in an ever-changing world. Ready to become a modern software engineer?
Language models generate responses based on the prompts they’re given. This makes prompt engineering—learning how to structure prompts—one of the most important aspects of working with large language models (LLMs) such as GPT-4 or LLaMA 2.
There are various ways to structure your prompts; some may be better suited for certain use cases. The better we can communicate with LLMs, the higher the probability of getting more relevant and consistent output from LLMs.
In this article, we will explore:
Some LLMs expose more settings than others, but four foundational ones are worth understanding. These will help you control the style and consistency of the model's output.
The temperature setting is a key parameter in LLM prompt engineering, controlling how predictable or creative the model’s responses will be. Lower temperatures result in more focused, consistent, and factual outputs, while higher temperatures introduce more variability and creativity.
When an LLM generates text, it selects the next word (or token) from a pool of possibilities, each with its own probability. For instance, when completing the phrase “The ocean is,” the model is more likely to choose tokens like “blue” or “deep.” Less probable options—like “furry” or “thin”—may still be considered, especially at higher temperature settings.
Raising the temperature essentially smooths out the differences between token probabilities, increasing the randomness of the result. Conversely, reducing the temperature sharpens the focus on the most likely continuation.
Setting the temperature to 0 aims to make the model fully deterministic, meaning it will always return the same output for the same input. However, due to minor randomness in GPU-level computations, this determinism may not be perfect in practice.
Beyond temperature, two additional settings—Top-K and Top-P—offer powerful ways to control the randomness and diversity of an LLM’s output. These are widely used in prompt engineering to fine-tune how a model selects the next word or token during generation.
Let’s continue with the earlier example based on the prompt “The ocean is”, and assume the model assigns the following probabilities to the next possible tokens:
Top-K sampling limits the model to choosing from the top K most probable tokens.
This method effectively filters out all tokens beyond the top-K, regardless of their actual probabilities.
Top-P sampling, also known as nucleus sampling, takes a different approach. Rather than selecting a fixed number of top tokens, it chooses the smallest possible set of tokens whose cumulative probability exceeds a given threshold P.
Using the same example:
Top-P is more adaptive than Top-K, because the number of candidate tokens can grow or shrink depending on the actual probability distribution.
These two techniques can be used together to create a refined balance between determinism and randomness.
For example, setting K = 3 and P = 0.7:
This combination allows you to exclude low-probability outliers while still maintaining some variability in output.
This setting determines how long the model’s output will be. It’s useful for tasks with strict output requirements or where you want to control cost (since many LLMs charge per token). It's especially helpful when asking for formats like JSON or bulleted lists.
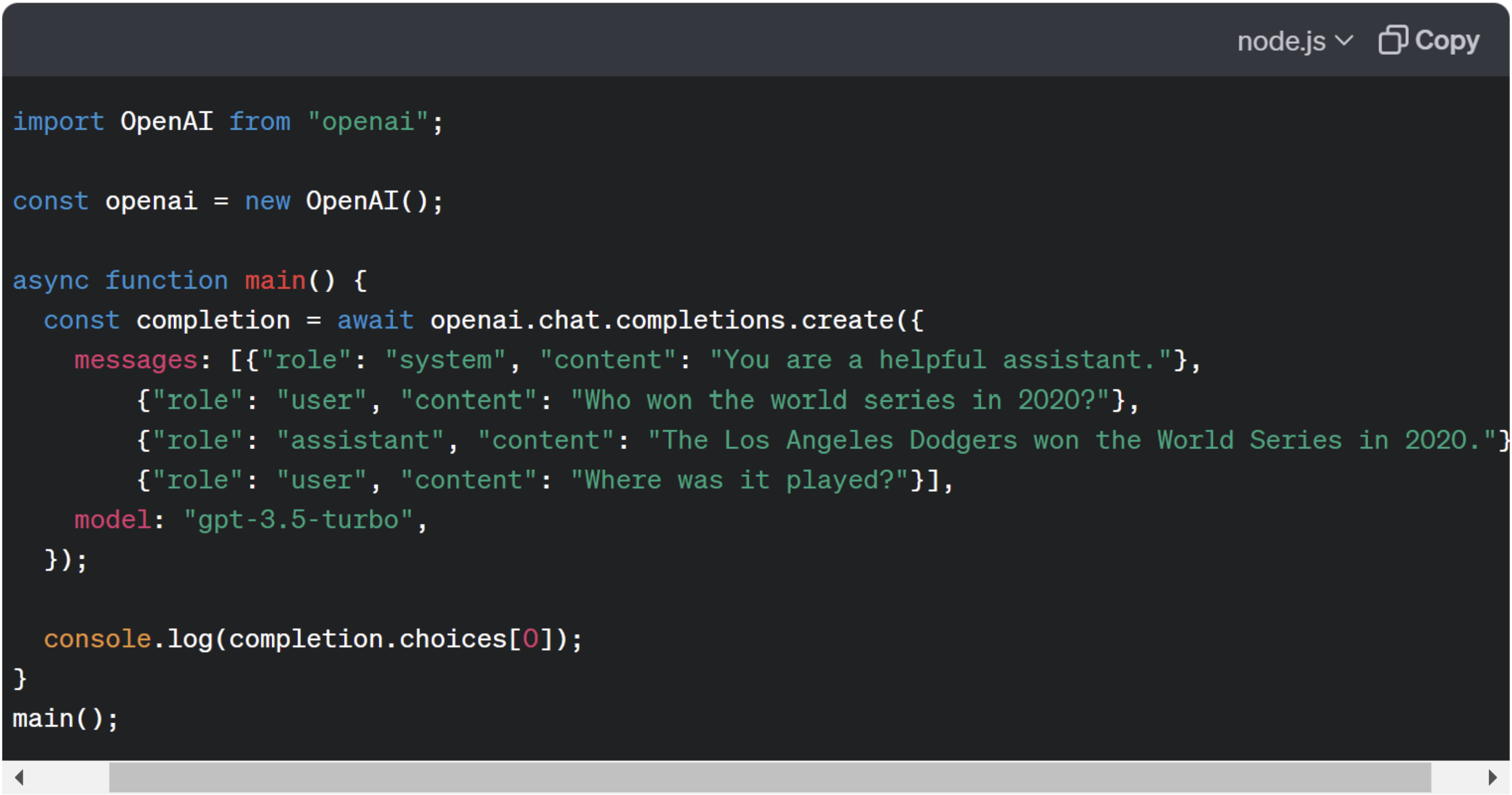
OpenAI’s chat-based LLMs use messages with roles to distinguish between different parts of a conversation:
Using a system message helps prime the model for certain types of behavior or response formats.
A table of prompt elements and their importance. Source: Author, based on Master the Perfect ChatGPT Prompt Formula (in just 8 minutes)! and https://www.youtube.com/watch?v=jC4v5AS4RIM
Let’s go over the distinct elements that make up a prompt. Note that not all elements need to be used in every prompt. Additionally, designing effective natural language prompts is crucial for guiding LLMs in producing accurate outputs.

The request or task that the LLM should perform. This is usually an action verb. For example, we can instruct the model to “analyze” collected feedback, “summarize” a report, “classify” sentiment, or “generate” headlines.
It is important to use separate instructions for clarity. This helps in effectively organizing the prompt by delineating different types of content such as instructions, examples, and questions.
The data that the LLM should perform the task on. If our instruction is to “classify the following text as positive, neutral, or negative,” then we need to provide the input text for the LLM to classify. For example, “The salesperson was helpful.”
External or additional information can steer the model to more relevant responses by narrowing down the endless possibilities. For instance, if we are instructing the LLM to “generate 3 business names,” the LLM has no clue what type of business we are talking about. So we can provide context to the instruction to be more specific, such as “generate 3 business names for a social media agency targeting trendy, anime shops.”
Examples that are provided to guide the LLM. Jeff Su provided the following exemplar prompt: “Rewrite the provided bullet point using this structure: I accomplished X by measure Y resulting in Z.” We then give an actual example that follows the structure: “I onboarded new clients by 2 days faster on average resulting in a 23% increase in client satisfaction score.”
Specification on who the LLM should be when carrying out the instruction. The persona could be a seasoned social marketing expert with 12 years of experience who is witty. Or we can name a specific famous individual (real or fictional), such as Steve Jobs or Wonder Woman.
Specification for the format and style of the LLM output.
We can tell the LLM to “generate 3 business names that are composed of 2 words.” Jeff Su provided the following format prompt: “Analyze collected feedback based on the responsible team (sales, support, or product) and output in table format with column headers: Feedback, Team, and Priority.” Some common formats include emails, bullet points, tables, code blocks, markdown, JSON, and paragraphs.
The voice or style of the output. For instance, friendly, professional, funny, empathetic, etc.
A static prompt consists of plain text without templating, dynamic injection, or external data. One key element of static prompting is the exemplar, where we may include zero, one, or a few examples to guide the LLM’s response. Including one or more examples often improves the accuracy and relevance of LLM output—particularly for more complex or ambiguous tasks. The effectiveness lies in selecting clear, concise, and informative examples (typically 2–5) that guide rather than overwhelm the model.
Zero-shot prompting is the simplest type of prompt. Modern LLMs like GPT-3.5 or GPT-4, trained on massive datasets, can perform tasks without any examples in the input. A well-phrased instruction is often enough to yield a coherent and relevant response, even if no prior context is given. This makes zero-shot prompting ideal for lightweight, fast implementations.

In the preceding zero-shot prompt example, although the prompt didn’t include any examples of input text and expected classification, the LLM was able to comprehend “sentiment” and classified it as neutral.
One-shot prompting involves supplying the LLM with a single example to guide its response. Compared to zero-shot prompts, this technique can help the model mimic a specific format or tone. One-shot prompts are effective when we need the LLM to replicate a pattern or reasoning method, offering improved alignment with the task intent.



Few-shot prompting provides the LLM with several examples to demonstrate a concept, pattern, or desired output format. This method is particularly useful when working with structured data or output formats that are difficult to describe using plain instructions. However, its performance depends heavily on the quality and relevance of the examples. While effective, few-shot prompting may struggle with complex or highly contextual tasks and often requires more human input, making it harder to scale programmatically.
The following example is a few-shot prompt tasking the LLM to extract a list of names and occupations in “First Last [OCCUPATION]” format from each news article without explicit instruction.


Prompt templating introduces variables into a static prompt, allowing for reusable and dynamic input generation. These templates use placeholders that are filled in at runtime, making prompts more scalable and programmatically manageable. Tools like LangChain or other LLM frameworks often support templating for tasks such as product recommendations, summaries, or content generation.

LLMs have a knowledge cutoff and lack access to private or real-time information. To provide up-to-date or domain-specific data, contextual prompting uses Retrieval Augmented Generation (RAG). External sources like databases, APIs, or document repositories supply relevant context during prompt execution. This approach is essential for use cases involving proprietary data, recent events, or personalized outputs.
The following example from OpenAI asks about the 2022 Winter Olympics, which is outside of the model’s knowledge base. Hence the LLM couldn’t answer the question. However, when provided with additional background, it provided the correct answer.


Chain-of-Thought prompting enhances LLM reasoning by encouraging step-by-step thinking. Unlike few-shot prompting that only shows input-output pairs, CoT examples walk through intermediate reasoning. It is particularly effective for tasks involving logic, mathematics, or complex decision-making. The key is to demonstrate the process—not just the result—to improve the model’s internal reasoning path.

The following example didn’t use the CoT prompting technique and the LLM correctly added the odd numbers to 41, but failed to detect that the assertive statement “The odd numbers in this group add up to an even number” is false.

With the CoT prompting technique, the LLM correctly added the odd numbers to 41 and also detected that the assertive statement “The odd numbers in this group add up to an even number” is false.

Zero-Shot CoT prompting adds simple reasoning cues like "Let’s think step by step" to a zero-shot prompt. This small addition often improves accuracy in reasoning-heavy tasks, even without providing examples. It's a quick and lightweight alternative to full CoT prompting when examples are unavailable or too costly to produce.
Using the previous arithmetic query with the Zero-Shot CoT prompting technique, the LLM correctly added the odd numbers to 41 and also detected that the assertive statement “The odd numbers in this group add up to an even number” is incorrect. However, without the examples, it didn’t respond in a consistent output format.

However, LLMs are evolving and getting more capable. Given just a zero-shot prompt, GPT-4 seems to apply the “Let’s think step by step” automatically in its response. However, the response contained contradictory statements of “The statement is true” and “So, the statement is incorrect.”

Auto-CoT prompting automates the generation of reasoning steps through a two-stage process:
This advanced technique reduces human effort and supports scalable prompt engineering in AI pipelines.

With the advent of multimodal LLMs like GPT-4V, which can process both text and images, Multimodal-CoT prompting combines visual and textual reasoning. It typically follows two stages:
This technique is ideal for complex visual question answering and multi-input reasoning.

While CoT prompting boosts logical reasoning, there’s no guarantee that the model’s reasoning path is always accurate. Due to the lack of transparency in LLMs, incorrect steps may still yield correct answers—or vice versa. Careful evaluation is essential when relying on CoT outputs in high-stakes applications.
Tree of Thoughts prompting goes beyond linear reasoning by simulating multiple paths to a solution. The LLM constructs a tree of intermediate thoughts and self-evaluates each step. Algorithms like breadth-first search and depth-first search help the model explore, backtrack, and select optimal solutions. ToT prompting excels in complex, multi-step reasoning tasks and mirrors human-like trial-and-error problem-solving.

ToT prompting is derived from the ToT framework and is an advanced technique for tackling complex tasks, like mathematical and logical reasoning.
Here is an example complex question by Dave Hulbert:
“Bob is in the living room. He walks to the kitchen, carrying a cup. He puts a ball in the cup and carries the cup to the bedroom. He turns the cup upside down, then walks to the garden. He puts the cup down in the garden, then walks to the garage. Where is the ball?”
When using the Zero-Shot CoT technique with GPT-3.5-Turbo-0125, an incorrect answer was given that the ball was in the garden.

The key to the ToT prompting technique is crafting an effective ToT-based prompt. Dave Hubert proposed the following ToT-based prompt based on the ToT framework:
“Imagine three different experts are answering this question. All experts will write down 1 step of their thinking, then share it with the group. Then all experts will go on to the next step, etc. If any expert realizes they’re wrong at any point then they leave. The question is…”
Providing Hubert’s ToT-based prompt to GPT-3.5-Turbo-0125 yielded the correct answer that the ball is in the bedroom.
However, GPT-4 answered correctly with a zero-shot prompt that the ball is in the bedroom. So more experimentation and observation are needed to determine whether ToT prompting will be necessary as LLMs improve their reasoning capability.

While prompt engineering can greatly enhance the performance of large language models (LLMs), it is not without challenges.
A key limitation of LLM prompt engineering is variability in outputs across different models. As shown in earlier examples, the same prompt can produce different responses from GPT-3.5-Turbo and GPT-4—two models developed by the same organization, OpenAI. This variation becomes even more pronounced when using prompts across LLMs from different providers, due to differences in architecture, training data, and fine-tuning methods. To ensure consistency, it’s important to test and adapt prompts for each LLM individually.
Prompt engineering requires careful design to avoid bias and misinformation. Techniques such as few-shot prompting, contextual input, and step-by-step reasoning rely on human-provided examples and data. If these inputs are flawed or biased, the model’s responses will reflect those issues. As the saying goes: garbage in, garbage out. While companies like OpenAI state that user-provided prompts via the API are not used to train their models (as of this writing), biases in inputs can still propagate into outputs. Being aware of this risk is critical in responsible LLM deployment.
An LLM (Large Language Model) is a type of artificial intelligence trained on vast amounts of text data to understand and generate human-like language. In prompt engineering, LLMs are guided using carefully crafted prompts to produce accurate, relevant, and task-specific outputs.
System prompts are high-level instructions provided to an LLM that help define its behavior. These prompts set parameters such as tone, domain expertise, response format, or limitations. System prompts are especially useful for tailoring the AI's behavior across different applications.
The three core prompting techniques are:
Each approach varies in complexity and use case, with few-shot prompting generally yielding the most structured responses.
LLMs interpret prompts by analyzing the input structure, extracting intent and context, and generating output based on patterns learned during training. Key parameters such as temperature, max tokens, and stop sequences also influence how the model responds.
To get the most out of large language models, mastering prompt structure and design is essential. A deep understanding of prompt elements, LLM settings, and advanced strategies like Chain-of-Thought prompting can significantly improve the accuracy and consistency of responses.
However, prompt engineering is an iterative process. Different models and tasks often require experimentation and refinement. Clear, structured prompts not only reduce ambiguity but also mitigate risks like bias and hallucination.
As LLM technology continues to evolve, so too will the strategies for interacting with them. Staying agile, testing different prompting techniques, and adapting your approach over time will help you unlock the full potential of LLMs in real-world applications.

Explore CS Prep further in our beginner-friendly program.
Get more free resources and access to coding events every 2 weeks.

Connect with one of our graduates/recruiters.

Our graduates/recruiters work at:

Short Bio goes here, lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.


Connect with one of our graduates/recruiters to learn about their journeys.
Our graduates/recruiters work at:
